Audio File Hashing
TheAudioDB stores hashes of popular music files submitted by our users.
Popular releases can have many hashes and we have an API available to look up these hashes and provide both TADB and musicbrainz ID's for them
So we looked into alternatives and the algorithm we settled on is based on a modified version of the OpenSubtitles.org code


Unlike the OpenSubtitles.org hash, in this case, the dual hash offset positions within the file are determined
by the file size to support smaller file sizes, while allowing larger TAG data (embedded images) to be changed
without affecting both hashes (unless the embedded image changes the file size from under 2048KiB to over 2048KiB).
The purpose of the hashing at offsets close to the start and the end of the file is to ensure that if a
TAG editing tool modifies either the beginning or the end of the file, at least one of the two hashes should
survive and allow us to get meta-data on a specific file.
 Download (Win32)
Download (Win32)
The App should be incredibly quick to use taking only a few minutes to hash your entire MP3 or FLAC collection.
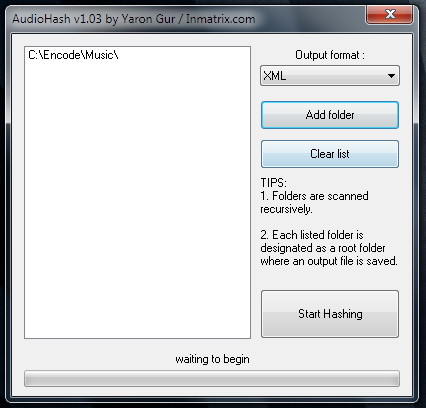
The output will look like this.

Example
http://www.theaudiodb.com/api/v1/json/1/search-hash.php?h1=5C9A5186D36C5CD0&h2=8B79EDB8090D16CB
Popular releases can have many hashes and we have an API available to look up these hashes and provide both TADB and musicbrainz ID's for them
About
We first looked at AcoustiID but found the algorithm too heavy (both CPU and bandwidth required).So we looked into alternatives and the algorithm we settled on is based on a modified version of the OpenSubtitles.org code
Unlike the OpenSubtitles.org hash, in this case, the dual hash offset positions within the file are determined
by the file size to support smaller file sizes, while allowing larger TAG data (embedded images) to be changed
without affecting both hashes (unless the embedded image changes the file size from under 2048KiB to over 2048KiB).
The purpose of the hashing at offsets close to the start and the end of the file is to ensure that if a
TAG editing tool modifies either the beginning or the end of the file, at least one of the two hashes should
survive and allow us to get meta-data on a specific file.
Source Code
You can download the Source Code(Delphi 7) for this technique here. We hope over time other developers will port this to other languagesHashing App
The App should be incredibly quick to use taking only a few minutes to hash your entire MP3 or FLAC collection.
Submitting Hashes
We no longer accept submitted hashes from normal users. But feel free to contact us if you think you have a nice hash collection.Hashing API
Our API provides fast searches on song hashes, you can find instructions for these hereThe output will look like this.
Example
http://www.theaudiodb.com/api/v1/json/1/search-hash.php?h1=5C9A5186D36C5CD0&h2=8B79EDB8090D16CB